현재 구조로는 Custom Repository Implementation을 사용 중
많은 필터가 쿼리문에 들어가기 때문에 기본적으로 제공하는 JPA를 사용할 수 없게 되어 사용하게 되었습니다.
문제점
전체를 select해서 조회하는 쿼리를 작성
전체 데이터와 전체 개수를 count하는 2개의 쿼리를 생성
아래코드는 where절을 뺀 코드 입니다. 상황에 맞게 추가하시면 될 것 같습니다.
필터값에 맞는 데이터를 List로 출력, 전체 데이터의 개수 2가지를 출력하는 메서드 입니다.
CustomRepositoryImpl.java
List<AllDataEntity> allDataEntities = jpaQueryFactory
.selectFrom(qAllDataEntity)
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
long contentCount = jpaQueryFactory
.from(qAllDataEntity)
.fetch().stream().count();
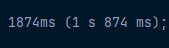
위와 같이 데이터를 조회하니 2초가량이 나옵니다.
코드를 보고 문제점을 파악하신 분들도 있을 수 있습니다.
하나하나 짚어보겠습니다.
1. fetch().stream().count()
- fetch()는 조건에 맞는 데이터를 전부 DB에서 가져와 메모리로 로드하며,
- stream().count()는 이 메모리상에 로드된 데이터에서 조건에 맞는 항목을 계산하여 개수를 반환합니다.
즉, 정리하면 데이터 전체를 DB에서 가져와 메모리 로드 후 계산을 진행하는 방식
메모리 사용량이 증가, 성능저하 발생 우려
long contentCount = jpaQueryFactory
.select(qAllDataEntity.count())
.from(qAllDataEntity)
.fetchOne();
if (contentCount == null) {
contentCount = 0L;
}
// null처리는 센스 ㅎㅎ
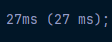
2. count()
- DB에서 직접 데이터를 세는 방법이며, 1번과 다른점은 DB에서 직접 가져오는 방식이기 때문에 메모리 사용량을 감소할 수 있습니다!
추가로 fetch는 리스트로 값이 반환되기 때문에 2번씩 같은 함수에서 사용하는 건 메모리 낭비와 DB과부하의 우려가 있습니다.
필터값과 상관없이 저는 DB에 저장된 모든 개수를 구해야 하기 때문에 fetchOne을 사용하여 count값만 나타내주었지만
fetch에서 출력된 값을 .size()함수를 사용하여 그대로 뽑아내는 것도 방법입니다.
long contentCount = allDataEntities.size();