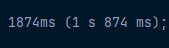
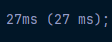
크롤링과 스크래핑?

크롤링 (Crawling) 뉴스 기사 수집
크롤링은 웹사이트의 모든 페이지를 탐색하며 정보를 수집 구조화하는 과정을 의미합니다.
크롤러가 자동으로 웹사이트의 페이지 링크를 따라가며 데이터를 수집합니다.
스크래핑 (Scraping) 유튜브 구독자 좋아요 등 수집
스크래핑은 웹 페이지의 특정 데이터만 추출하는 작업을 의미합니다.
주로 특정 웹사이트에서 필요한 데이터만을 추출하여 가공하는 데 사용됩니다.
- 크롤링: 웹사이트 전체 또는 다수의 페이지를 대상으로 데이터 수집
- 스크래핑: 특정 페이지에서 필요한 데이터만 추출


스크래핑은 별점과 같은 특정 정보를 가져오는 것을 의미


크롤링은 url을 이동하며 웹페이지를 조작해 데이터를 수집하는 것을 의미
url, 작성자, 날짜 등의 정보를 수집하기 위해선 Locator가 필요
Locator → DOM 트리에서 특정 요소를 선택하는 데 사용
DOM 문서 객체 모델(Document Object Model) → HTML, XML 문서를 표현하고 조작하는 데 사용되는 프로그래밍 인터페이스
Locator란 즉, CSS selector, Xpath를 가르킴
DOMtree란 html코드의 구조를 계층적으로 나타낸 것을 의미
*****HTML*****
<!DOCTYPE html>
<html>
<head>
<title>Let's crawling</title>
</head>
<body>
<h1>crawling Nice</h1>
<p>crawling</p>
</body>
</html>
*****DOMTREE*****
html
├── head
│ └── title
│ └── "Let's crawling"
└── body
├── h1
│ └── "crawling Nice"
└── p
└── "crawling"
DOMtree의 요소는 노드로 표시
- 루트 노드 (Root Node): 트리의 최상위 노드로, HTML 문서 전체를 나타냅니다.
- 요소 노드 (Element Node): HTML 요소를 나타내며, 트리의 가지(branch)에 해당합니다.
- 텍스트 노드 (Text Node): HTML 요소의 텍스트 내용을 나타냅니다.
DOMTREE형으로 구조화 하여 css xpath 원하는 요소를 찾는 것이 중요

css selector



css selector는 컴포넌트화된 환경에서 유일한 선택자를 찾기 어려움.
<div class="container">
<div class="item">
<h2>Title</h2>
<p>Content</p>
</div>
<div class="item">
<h2>text</h2>
<p>item</p>
</div>
</div>
div.item p -> 텍스트 기반으로 검색할 수 없어 2개의 p태그가 선택됨
이걸 xpath화 시키면
//div[@class="container"]/div[@class="item"]/h2[text()="text"]/following-sibling::p
2번째 p태그를 찾을 수 있음
 <xpath>
<xpath>
 <css selector>
<css selector>
부모 및 자식 선택
- ancestor: 현재 노드의 모든 조상 노드를 선택합니다.
- descendant: 현재 노드의 모든 후손 노드를 선택합니다.
- XPath: XPath에서는 // 연산자를 사용하여 문서의 모든 위치에서 요소를 선택할 수 있습니다. 또한 ancestor 및 descendant 축을 사용하여 특정 요소의 조상 또는 후손 요소를 선택할 수 있습니다.
- CSS 선택자: CSS 선택자는 > 및 공백을 사용하여 특정 요소의 직계 자식 또는 하위 요소를 선택할 수 있습니다. 그러나 CSS 선택자에는 조상요소를 선택하는 방법이 없습니다.
- 직계 자식 선택: .parent > .child
- 하위 요소 선택: .container .descendant
형제 선택
- following-sibling: 현재 노드의 다음 형제 노드들을 선택합니다.
- preceding-sibling: 현재 노드의 이전 형제 노드들을 선택합니다.
- XPath: XPath에서는 following-sibling 및 preceding-sibling 축을 사용하여 현재 요소의 다음 형제 또는 이전 형제 요소를 선택할 수 있습니다.
- CSS 선택자: CSS 선택자에서는 + 및 ~ 연산자를 사용하여 현재 요소의 다음 형제 요소를 선택할 수 있습니다. 그러나 이전 형제 요소를 선택하는 방법은 없습니다. (+ 는 다음 요소중 첫번째, ~ 형제요소중 p 요소)

css selector -> p + span (이전 선택 X)
- 다음 형제 선택: //p/following-sibling::span[1]
- 이전 형제 선택: //span/preceding-sibling::p[1] -> ??? 뭐가 선택될지
자식선택
- XPath: XPath에서는 child 축을 사용하여 현재 요소의 모든 자식 요소를 선택할 수 있습니다.
- CSS 선택자: CSS 선택자에서는 공백을 사용하여 현재 요소의 모든 하위 요소를 선택할 수 있습니다.

.container .child span:nth-child(2)
//div[@class="parent"]/div[@class="child"]/span[2]
or
//div[@class="parent"]/div[@class="child"]/span[text()='두 번째 스팬']
xpath 장점
- 양방향 제어 가능 (부모 자식 상위 하위 검색가능)
- 축(Axes)/함수를 사용하여 특정 노드 선택가능
- 최신 및 구식 브라우저도 호환가능
단점
- shadow DOM에는 사용 불가능(iframe -> 개별화된 DOM tree)
- 속도가 느리고 복잡함
css selector 장점
- 속도가 빠르고 읽기 쉬우며 배우기 쉬움
- 단일 제어이므로 안정적
단점
- 단방향이므로 제한적임
- 복잡하거나 컴포넌트화 되어있으면 로케이터를 구성하기 어려움
- 텍스트를 기반으로 selector를 구성하지 못함

Xpath Vs CSS Selector: Key Differences
XPath vs CSS selector Key differences explained with examples, this blog helps to choose the best locators for the automation framework.
testsigma.com